























































Aplikacje technologii sztucznej inteligencji (AI) w Przemysłowym Internecie Rzeczy (IIoT) oraz przetwarzanie danych na krawędzi sieci (edge computing) przynoszą firmom przemysłowym korzyści w postaci podejmowania decyzji w czasie rzeczywistym oraz bardziej inteligentnych działań na obiektach w terenie. Artykuł przedstawia porady na temat doboru komputerów brzegowych oraz narzędzi do tworzenia aplikacji programowych Sztucznej Inteligencji Rzeczy (AIoT).
Aplikacje Przemysłowego Internetu Rzeczy generują obecnie więcej danych niż cokolwiek przedtem. W wielu zastosowaniach przemysłowych, szczególnie w wysoce rozproszonych systemach zlokalizowanych w odległych obszarach, regularne wysyłanie wielkich ilości surowych danych do centralnego serwera może nie być możliwe. Aby zmniejszyć latencję oraz koszty przesyłu i przechowywania danych, jednocześnie zwiększając dostępność sieci, firmy przenoszą obecnie sztuczną inteligencję (AI) oraz uczenie maszynowe (ML) na krawędzie swoich sieci. Umożliwia im to podejmowanie decyzji oraz działań w czasie rzeczywistym na obiektach w terenie.
Aplikacje, które wykorzystują możliwości technologii AI w infrastrukturach Internetu Rzeczy (IoT) nazywane są Sztuczną Inteligencją Rzeczy (Artificial Intelligence of Things, AIoT). Chociaż trening modeli AI nadal odbywa się w chmurze, to zbieranie danych oraz inferencja (wnioskowanie; ang. inferencing) mogą być wykonywane na obiektach w terenie poprzez wdrożenie wytrenowanych modeli AI w komputerach brzegowych. Aby przygotować się do wdrożenia AIoT, należy najpierw dobrać właściwy komputer brzegowy dla danej aplikacji przemysłowej tej technologii.
Wprowadzanie AI do IIoT
Pojawienie się technologii Przemysłowego Internetu Rzeczy umożliwiło wielu firmom z różnych gałęzi przemysłu zbieranie ogromnych ilości danych z poprzednio niedostępnych źródeł oraz eksplorowanie nowych dróg do zwiększenia wydajności produkcji. Poprzez otrzymywanie danych na temat funkcjonowania i danych środowiskowych z urządzeń obiektowych oraz maszyn przedsiębiorstwa mają teraz większą ilość informacji potrzebnych do podejmowania bardziej świadomych decyzji. Ilość danych z sieci IIoT dalece przekracza zdolności człowieka do samodzielnego ich przetworzenia, co oznacza, że większość tych danych nie jest analizowana i wykorzystana. Firmy i eksperci od przemysłu zwracają się obecnie ku oprogramowaniu AI i ML dla aplikacji IIoT w celu otrzymania całościowego obrazu funkcjonowania zakładów oraz szybszego podejmowania bardziej inteligentnych decyzji.
Większość danych z IIoT pozostaje nieanalizowana
Zdumiewająco wielka liczba urządzeń przemysłowych podłączonych do Internetu gwałtownie wzrasta i oczekuje się, że w roku 2025 osiągnie wartość 41,6 miliarda punktów końcowych. Jednak bardziej zadziwiające jest to, ile danych produkuje każde z tych urządzeń. Manualne analizowanie wszystkich informacji generowanych przez czujniki zainstalowane na linii produkcyjnej mogłoby zabrać człowiekowi całe jego życie. Nie ma się co dziwić, że „mniej niż połowa ustrukturyzowanych danych przedsiębiorstwa jest aktywnie wykorzystywana przy podejmowaniu decyzji, a mniej niż 1% nieustrukturyzowanych danych tego przedsiębiorstwa jest analizowany lub w ogóle wykorzystywany”. To wniosek z badań przeprowadzonych w różnych gałęziach przemysłu, będący cytatem z artykułu „Jaka jest Wasza strategia danych?”
W przypadku kamer IP jedynie 10% z niemal 1,6 eksabajta (1EB = 1018 bajtów) generowanych codziennie danych wideo zostaje poddane analizie. Liczby te pokazują szokująco dużą ilość danych, które są pomijane w analityce pomimo istnienia możliwości przekształcania ich na wartościowe informacje. Ten brak możliwości analizowania ręcznego przez ludzi wszystkich generowanych danych jest przyczyną poszukiwania przez firmy przemysłowe sposobów włączania technologii AI oraz ML do aplikacji IIoT.
Wyobraźmy sobie, że fabryka produkująca piłki golfowe wykorzystuje do kontroli jakości wyrobów jedynie ludzi, którzy wzrokowo przez 8 godzin dziennie i 5 dni w tygodniu wychwytują drobne defekty tych piłek, schodzących z linii produkcyjnej. Można zatrudnić nawet całą armię kontrolerów jakości, jednak każdy z nich jest naturalnie podatny na zmęczenie oraz popełnianie błędów. Podobnie jest w przypadku kontrolowania przytwierdzeń szyn kolejowych. Może być ono wykonywane tylko w nocy, gdy pociągi nie kursują na danej trasie. Zadanie to jest nie tylko czasochłonne, ale i trudne do wykonania. Albo inspekcje linii energetycznych wysokiego napięcia czy aparatów elektrycznych na podstacjach, wykonywane przez ludzi. Prace te są ponadto niebezpieczne.

Łączenie technologii AI oraz IIoT
W każdej z omówionych wyżej sytuacji technologia AIoT daje możliwość zmniejszenia kosztów pracy, błędów ludzkich oraz optymalizacji konserwacji zapobiegawczej. AIoT odnosi się do zaadoptowania różnych technologii AI w aplikacjach Internetu Rzeczy (IoT) w celu zwiększenia efektywności operacyjnej, interakcji człowieka z maszyną oraz analityki i zarządzania danymi. Ale co rozumie się przez AI i jak pasuje ona do IIoT?
Sztuczna inteligencja jest ogólną dziedziną nauki, która bada, w jaki sposób można konstruować inteligentne maszyny oraz tworzyć inteligentne programy sterujące w celu rozwiązywania problemów, z którymi tradycyjnie radzi sobie ludzka inteligencja. AI zawiera uczenie maszynowe (ML), które jest specyficzną dziedziną, zajmującą się umożliwianiem systemom automatycznej nauki oraz ulepszania swojego działania za pomocą uzyskiwanego doświadczenia bez konieczności programowania przez człowieka. ML wykorzystuje do tego celu różne algorytmy oraz sieci neuronowe. Innym, związanym z omawianym tematem terminem jest „głębokie uczenie” (deep learning, DL), będące dziedziną ML. DL wykorzystuje wielowarstwowe sieci neuronowe, które uczą się na podstawie wielkiej ilości danych.
Ponieważ AI jest tak rozległą dyscypliną, w dalszej części artykułu omówimy, w jaki sposób wizja komputerowa (computer vision) lub oparta na AI analityka wideo, będące innymi dziedzinami AI, często wykorzystywane w połączeniu z ML, są wykorzystywane do klasyfikacji i rozpoznawania w przemyśle.
Wizja komputerowa i analityka wideo umożliwiają obecnie firmom przemysłowym i nie tylko uzyskanie większej wydajności produkcji oraz efektywności działania. Zastosowania tych technologii obejmują między innymi: odczyt danych z monitoringu odległych zasobów, konserwację zapobiegawczą, identyfikację pojazdów w celu sterowania sygnalizacją świetlną w inteligentnych systemach transportowych, drony wykorzystywane w rolnictwie, roboty patrolujące teren czy ulice, automatyczną inspekcję optyczną (automatic optical inspection, AOI) drobnych defektów produkcyjnych piłek golfowych oraz innych wyrobów.
Przenoszenie AI na krawędź sieci IIoT
Rozprzestrzenianie się systemów IoT powoduje generowanie olbrzymich ilości danych. Na przykład wielka ilość czujników i urządzeń w dużej rafinerii ropy naftowej generuje każdego dnia około 1 TB surowych danych. Odsyłanie tych wszystkich danych do chmury publicznej czy prywatnego serwera w celu przetwarzania i zapisywania wymagałoby dostępu do sieci znacznej przepustowości oraz powodowało duże zużycie energii elektrycznej. W wielu zastosowaniach przemysłowych i szczególnie wysoce rozproszonych systemach zlokalizowanych w odległych obszarach ciągłe wysyłanie dużych ilości danych do centralnego serwera nie jest możliwe.
Jeśli nawet firmy posiadają wystarczającą infrastrukturę sieci o odpowiedniej przepustowości, która jest bardzo droga w zainstalowaniu oraz utrzymywaniu, to nadal będzie istniało duże opóźnienie przesyłu i analizy danych. Najważniejsze dla przemysłu aplikacje muszą być w stanie analizować surowe dane tak szybko, jak to tylko jest możliwe.
Aby zmniejszyć opóźnienia przesyłu danych (latencję), zredukować ilość tych danych oraz koszty ich przechowywania, a przy tym zwiększyć dostępność sieci, aplikacje IIoT przenoszą obecnie możliwości technologii AI i ML na krawędź sieci. Pozwala to realizować wstępne przetwarzanie danych za pomocą urządzeń o dużej mocy obliczeniowej bezpośrednio na obiektach w terenie. Postępy w komputerach brzegowych, polegające na zwiększeniu ich mocy obliczeniowej, umożliwiły aplikacjom IIoT wykorzystanie możliwości AI podejmowania decyzji już w odległych lokalizacjach.
Dzięki podłączeniu urządzeń obiektowych do komputerów brzegowych, wyposażonych w procesory o dużej mocy obliczeniowej oraz technologię AI, nie ma już potrzeby wysyłania wszystkich generowanych na obiektach danych do chmury w celu przeprowadzenia ich analizy. W rzeczywistości oczekuje się, że dane generowane i przetwarzane w miejscach znajdujących się daleko od krawędzi oraz blisko krawędzi sieci wzrośnie do roku 2025 z 10 do 75%, natomiast ogólny rynek sprzętu do przetwarzania na krawędzi sieci uzyska do roku 2024 skumulowany roczny wskaźnik wzrostu (compound annual growth rate, CAGR) w wysokości 20,64%.
Wybór właściwego komputera brzegowego dla przemysłowej aplikacji AIoT
Przy wprowadzaniu AI do przemysłowych aplikacji IoT należy przeanalizować kilka kluczowych kwestii. Chociaż obecnie większość zadań związanych z trenowaniem modeli AI nadal jest realizowana w chmurze, to firmy przemysłowe w końcu będą jednak musiały wdrożyć wytrenowane modele inferencyjne na obiektach w terenie. Przetwarzanie danych na krawędzi sieci przy wykorzystaniu technologii AIoT zasadniczo umożliwia inferencję AI na obiektach zamiast wysyłania surowych danych do chmury w celu przetworzenia i analizy. Aby skutecznie uruchomić modele i algorytmy AI, przemysłowe aplikacje AIoT wymagają niezawodnej platformy sprzętowej, zainstalowanej na krawędzi sieci. Aby wybrać właściwą platformę sprzętową dla aplikacji AIoT, należy wziąć pod uwagę następujące czynniki:
- Wymagania dotyczące przetwarzania danych dla różnych faz wdrażania AI.
- Poziomy przetwarzania danych na krawędzi sieci.
- Narzędzia deweloperskie.
- Środowisko pracy.
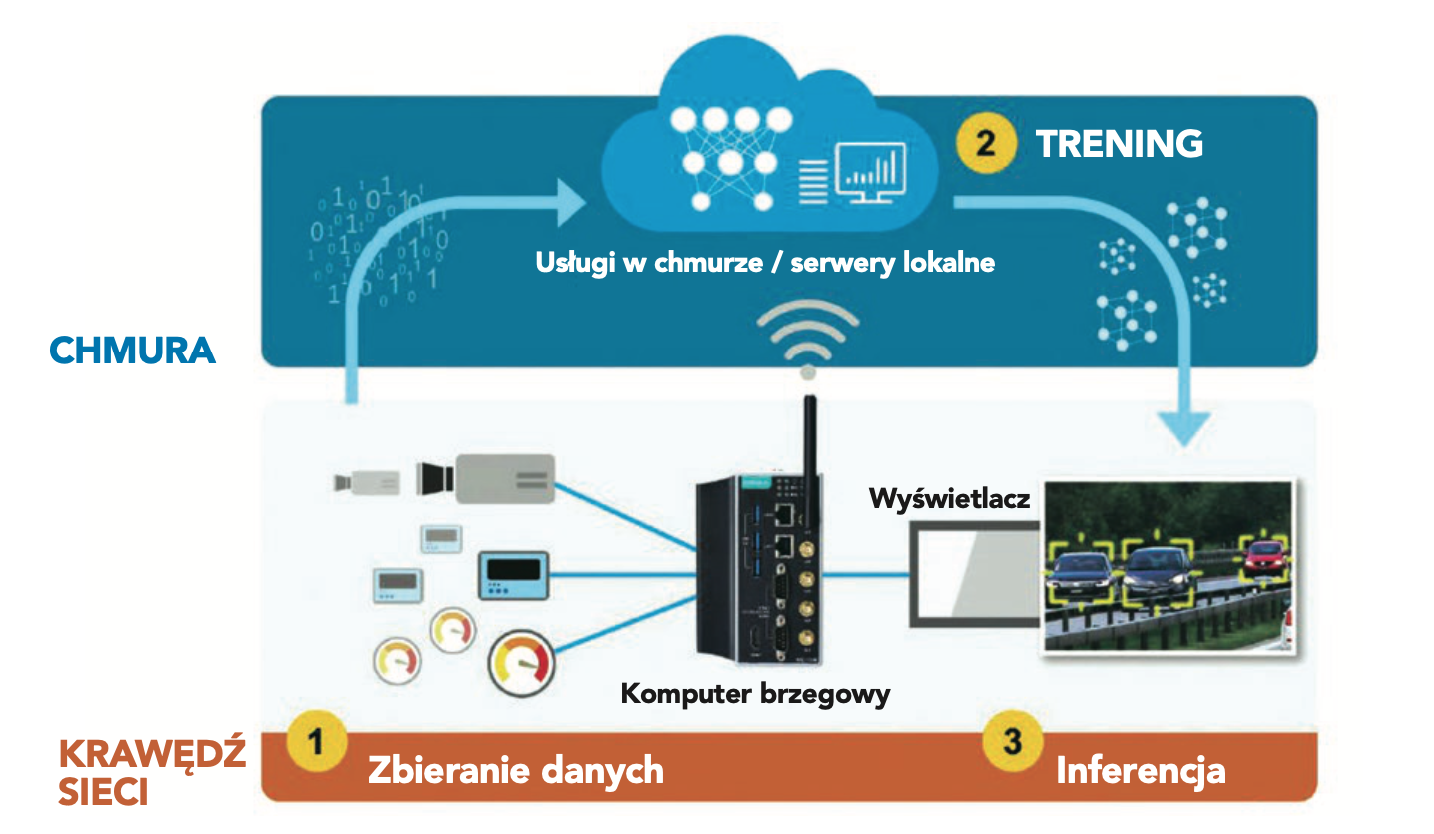
Wymagania dotyczące przetwarzania danych dla różnych faz wdrażania AI
Ogólnie mówiąc, na wymagania dotyczące przetwarzania danych dla AI mają wpływ takie czynniki jak wielkość mocy obliczeniowej wymaganej przez aplikacje oraz to, czy jest wymagana jednostka centralna (CPU) lub akcelerator. Ponieważ każda z następujących trzech faz w tworzeniu aplikacji AI do przetwarzania danych na krawędzi wykorzystuje różne algorytmy do wykonywania różnych zadań, każda z tych faz będzie miała swój własny zbiór wymagań dotyczących przetwarzania danych.
Trzy fazy tworzenia aplikacji AIoT
Trzy fazy tworzenia aplikacji to zbieranie danych, trening oraz inferencja. Szczegóły opisano poniżej:
- Zbieranie danych. Celem tej fazy jest uzyskanie wielkich ilości informacji, potrzebnych do wytrenowania modelu AI. Same surowe, nieprzetworzone dane, nie są pomocne, ponieważ informacje mogą zawierać powielenia, błędy oraz wartości znacznie odbiegające od innych. Wstępne przetworzenie zebranych danych w fazie początkowej w celu identyfikacji wzorców, wartości odbiegających od innych oraz brakujących informacji pozwala też użytkownikom skorygować błędy i przekłamania. W zależności od złożoności zebranych danych platformy obliczeniowe, wykorzystywane typowo w zbieraniu danych, są zwykle oparte o procesory Arm Cortex lub Intel Atom. Z reguły dla wykonywania zadań związanych ze zbieraniem danych ważniejsze są specyfikacje dotyczące wejść/wyjść (I/O) oraz CPU niż procesora graficznego (GPU).
- Trening. Modele AI muszą być wytrenowane za pomocą zaawansowanych sieci neuronowych oraz wymagających algorytmów ML lub DL. Algorytmy te do analizy dużych ilości zbieranych i wstępnie przetworzonych danych potrzebują podzespołów komputerowych o wyższych parametrach, takich jak procesory graficzne o dużej mocy obliczeniowej. W trakcie tego procesu nie ma potrzeby oceny czy dostrajania parametrów, aby zapewnić dokładność. Do wyboru jest wiele modeli i narzędzi treningowych, w tym dostępne na rynku platformy projektowe DL, takie jak PyTorch, TensorFlow i Caffe. Trening jest zwykle wykonywany na wyznaczonych maszynach treningowych AI lub za pomocą usług w chmurze, takich jak AWS Deep Learning AMIs czy SageMaker Autopilot firmy Amazon, Google Cloud AI lub Microsoft Azure Machine Learning.
- Inferencja. Jest to końcowa faza, która obejmuje wdrożenie wytrenowanego modelu na komputerze brzegowym, dzięki czemu potrafi on szybko i wydajnie dokonywać wnioskowania (inferencji) oraz prognozowania na podstawie nowo zebranych i wstępnie przetworzonych danych. Ponieważ faza inferencji zużywa w zasadzie mniej zasobów obliczeniowych niż trening, dla aplikacji AIoT wystarczająca może okazać się jednostka CPU lub lekki akcelerator. Potrzebne jest jednak narzędzie do konwersji wytrenowanego modelu, aby mógł być on uruchomiony na wyspecjalizowanych procesorach/akceleratorach brzegowych, takich jak OpenVINO firmy Intel lub CUDA firmy NVIDIA.
Poziomy i architektury przetwarzania danych na krawędzi sieci
Chociaż trening modeli AI jest nadal wykonywany w chmurze lub na lokalnych serwerach, zbieranie danych oraz inferencja koniecznie mają miejsce na krawędzi sieci. Ponadto, ponieważ inferencja ma miejsce tam, gdzie wytrenowany model AI wykonuje większość pracy nad realizacją zadań aplikacji takich jak podejmowanie decyzji lub wykonywanie działań na podstawie nowo zebranych danych z obiektów, istnieje potrzeba określenia, który z następujących poziomów przetwarzania danych na krawędzi będzie wymagany, aby odpowiednio dobrać procesor.
Niski poziom przetwarzania danych na krawędzi. Przesyłanie danych z krawędzi sieci do chmury jest drogie i czasochłonne, ponadto występuje przy tym latencja. Przy przetwarzaniu danych na krawędzi na niskim poziomie tylko niewielka ilość użytecznych danych jest wysyłana do chmury, co zmniejsza czas opóźnienia przesyłu, wymaganą przepustowość sieci, opłaty za przesył danych oraz koszty sprzętu i zużytej energii. Platforma oparta na procesorach ARM bez akceleratorów może być wykorzystana dla urządzeń IIoT do zbierania i analizowania danych w celu szybkiego wnioskowania lub podejmowania decyzji.
Średni poziom przetwarzania danych na krawędzi. Na tym poziomie inferencji mogą być obsługiwane różne strumienie wideo z kamer IP, przeznaczone dla wizji komputerowej lub analityki wideo. Ilość przetwarzanych klatek na sekundę jest wystarczająca. Przetwarzanie danych na średnim poziomie obejmuje szeroki zakres złożoności danych zależnie od modelu AI oraz wymagań dotyczących wydajności dla danego przypadku. Mogą to być aplikacje do rozpoznawania twarzy w systemie nadzorującym wejście do biura lub też sieć nadzorująca duży obszar o dostępie publicznym. Większość przemysłowych aplikacji do przetwarzania danych na krawędzi sieci wymaga też uwzględnienia ograniczeń mocy zasilania lub konstrukcji zawierających radiatory bez wentylatora. Na tym poziomie możliwe jest wykorzystanie jednostki CPU o dużej mocy obliczeniowej, wejściowego procesora GPU lub jednostki przetwarzania wizyjnego (vision processing unit, VPU). Na przykład procesory z serii Intel Core i7 oferują wydajne rozwiązanie dla przetwarzania wizyjnego wraz z zestawem narządzi OpenVINO oraz akceleratorami programowymi AI/ML, które mogą wykonywać inferencję na krawędzi sieci.
Wysoki poziom przetwarzania danych na krawędzi. Wysoki poziom obejmuje przetwarzanie dużych ilości danych przeznaczonych dla eksperckich systemów AI, które wykorzystują bardziej złożone rozpoznawanie wzorców. Są to takie systemy jak analizujący zachowanie w systemach zautomatyzowanego nadzoru wideo w miejscach publicznych, który wykrywa incydenty zagrażające bezpieczeństwu lub stwarzające potencjalne zagrożenia. Do inferencji w systemach przetwarzania danych na wysokim poziomie w zasadzie wykorzystywane są akceleratory zawierające wysokiej klasy procesory GPU i VPU, procesory Google TPU (Tensor Processing Unit) lub bezpośrednio programowalne macierze bramek (field programmable gate array, FPGA), które pobierają dużą moc (200 W lub więcej) i wydzielają dużo ciepła. Ponieważ wymagania dotyczące mocy zasilania oraz chłodzenia mogą przekraczać dostępne wartości na odległych krawędziach sieci, takich jak np. jadący pociąg, systemy przetwarzania danych na wysokim poziomie są często wdrażane w miejscach w pobliżu krawędzi sieci, takich jak np. stacja kolejowa, aby mogły wykonywać swoje zadania.
Narzędzia deweloperskie dla AI oraz aplikacje ML
Dostępnych jest kilka narzędzi dla różnych platform sprzętowych, które pomagają przyśpieszyć proces tworzenia aplikacji lub poprawić ogólną wydajność algorytmów AI i ML.
Platformy głębokiego uczenia
Rozważmy użycie platformy DL, która jest interfejsem, biblioteką lub narzędziem, umożliwiającym użytkownikom łatwe i szybkie budowanie modeli głębokiego uczenia bez zagłębiania się w szczegóły wykorzystywanych algorytmów. Platformy głębokiego uczenia są jasną i zwięzłą metodą definiowania modeli przy wykorzystaniu zbioru wstępnie zbudowanych i zoptymalizowanych komponentów. Trzy najbardziej popularne platformy to:
- PyTorch. Pierwotnie opracowana przez należące do Facebooka laboratorium AI Research Lab. Jest to darmowa biblioteka ML typu open source, oparta na bibliotece Torch. Jest wykorzystywana dla takich aplikacji jak wizja komputerowa i przetwarzanie języka naturalnego (natural language processing, NLP). PyTorch jest wydawana na zmodyfikowanej licencji BSD (Berkeley Software Distribution License).
- TensorFlow. Umożliwia szybkie prototypowanie, badania i produkcję. Wykorzystuje łatwe w obsłudze interfejsy programowania aplikacji (API), oparte na platformie Keras. Są one używane do definiowania i trenowania sieci neuronowych.
- Caffe. Ma wyrazistą architekturę, która pozwala użytkownikom definiować i konfigurować modele i dokonywać optymalizacji bez sztywnego kodowania (hard coding). Wystarczy ustawić pojedynczą flagę, aby wytrenować model na maszynie GPU, a następnie wdrożyć go w prostych komputerach czy urządzeniach mobilnych.
Zestawy narzędzi dla akceleratorów sprzętowych
Zestawy narzędzi dla akceleratorów AI są oferowane przez producentów sprzętu komputerowego. Są one specjalnie zaprojektowane do przyśpieszania aplikacji AI, takich jak ML oraz wizja komputerowa na ich platformach. Są to:
- OpenVINO firmy Intel. Zestaw narzędzi OpenVINO (Open Visual Inference and Neural Network Optimization) jest przeznaczony do pomocy deweloperom oprogramowania w tworzeniu niezawodnych aplikacji wizji komputerowej na platformach firmy Intel. OpenVINO umożliwia też szybszą inferencję dla modeli DL.
- CUDA firmy NVIDIA. Zestaw narzędzi CUDA umożliwia wykonywanie bardzo wydajnego, równoległego przetwarzania danych dla aplikacji przyśpieszanych przez procesory GPU w systemach wbudowanych, centrach danych, platformach w chmurze oraz superkomputerach zbudowanych przy wykorzystaniu uniwersalnej architektury procesorów wielordzeniowych (Compute Unified Device Architecture) firmy NVIDIA.
Lokalizacja sprzętu wykorzystującego technologię AI oraz ML – znaczenie warunków otoczenia
Ostatnim, ale wcale nie mniej ważnym punktem do rozważenia jest fizyczna lokalizacja sprzętu wykorzystującego technologie AI oraz ML. Urządzenia przemysłowe znajdujące się na zewnątrz budynków lub pracujące w trudnych warunkach otoczenia (takie jak w inteligentnych miastach, rafineriach ropy naftowej, szybach naftowych i gazowych, kopalniach, instalacjach energetycznych, a także w robotach patrolujących) powinny być przystosowane do pracy w szerokim zakresie temperatur oraz posiadać odpowiednie układy chłodzenia, aby mogły działać zarówno podczas upałów, jak i mrozów. Niektóre urządzenia wymagają ponadto specyficznych dla przemysłu certyfikatów lub cech konstrukcyjnych, takich jak chłodzenie bezwentylatorowe, obudowa przeznaczona dla strefy zagrożonej wybuchem oraz odporność na wibracje. Ponieważ w praktyce wiele urządzeń jest instalowanych w szafach sterowniczych o małej przestrzeni i podlega ograniczeniom co do wymiarów, preferowane są komputery brzegowe o małych gabarytach.
Wysoce rozproszone urządzenia przemysłowe, znajdujące się w odległych miejscach, mogą też wymagać niezawodnej komunikacji sieciowej, realizowanej za pomocą sieci komórkowej lub Wi-Fi. Na przykład przemysłowy komputer brzegowy posiadający zintegrowaną kartę sieciową LTE eliminuje potrzebę instalowania dodatkowej komórkowej bramy sieciowej. Dzięki temu uzyskuje się znaczne oszczędności przestrzeni w szafach sterowniczych oraz kosztów. Inną kwestią do rozważenia jest tu zastosowanie redundantnego bezprzewodowego połączenia sieciowego za pomocą karty dual SIM. Może to być potrzebne do zapewnienia przesyłu danych w sytuacji, gdy w danym miejscu sygnał sieci komórkowej jest słaby lub zanika.
AI zwiększa efektywność operacyjną oraz redukuje koszty
Wykorzystanie możliwości technologii AI na krawędzi sieci pozwala firmom zwiększyć efektywność operacyjną oraz zredukować ryzyka i koszty dla aplikacji przemysłowych. Proces wyboru właściwej platformy obliczeniowej dla przemysłowej aplikacji AIoT powinien także obejmować uwzględnienie specyficznych wymagań dla przetwarzania danych we wszystkich trzech opisanych w artykule fazach wdrożenia: zbierania danych, trenowania oraz inferencji. W tej ostatniej fazie należy ponadto określić poziom przetwarzania danych na krawędzi sieci (niski, średni lub wysoki), aby dobrać optymalny typ procesora.
Należy wybrać komputer brzegowy najlepiej dopasowany do wykonywania przemysłowych zadań związanych z inferencją AI na obiektach w terenie, oceniając specyficzne wymagania aplikacji AIoT w każdej fazie.
Ethan Chen i Alicia Wang pracują na stanowiskach menedżerów produktu w firmie Moxa.